Параллельные и распределенные вычисления
Семинар 4
CUDA
Пономаренко Роман
@rerand0m
rerandom@ispras.ru

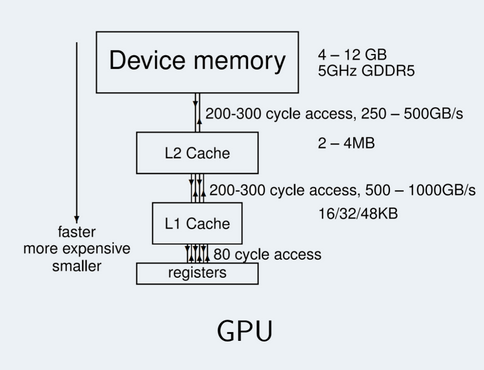
Параметры, доступные потоку
dim3 gridDimdim3 blockDimuint3 blockIdxuint3 threadIdx
func<<<gridDim, blockDim>>>(...)
blockDim (число потоков)
- Максимальная размерность - 1024 x 1024 x 64
- Максимальное количество потоков - 1024
- Примеры:
- 32 x 32 x 1 - Ok
- 16 x 16 x 4 - Ok
- 512 x 2 x 1 - Ok
- 4 x 4 x 64 - Ok
- 128 x 64 x 1 - Fail
- 2 x 2 x 128 - Fail
Немного о матрицах
const long WIDTH = 100;
const long HEIGHT = 100;
float** matrix0;
const long WIDTH = 100;
const long HEIGHT = 100;
float* matrix1;
Немного о матрицах
const long WIDTH = 100;
const long HEIGHT = 100;
float** matrix0;
// Аллокация
matrix0 = new float*[HEIGHT];
for (int i = 0; i < HEIGHT; ++i)
matrix0[i] = new float[WIDTH];
const long WIDTH = 100;
const long HEIGHT = 100;
float* matrix1;
// Аллокация
matrix1 = new float[WIDTH*HEIGHT];
Немного о матрицах
const long WIDTH = 100;
const long HEIGHT = 100;
float** matrix0;
// Аллокация
matrix0 = new float*[HEIGHT];
for (int i = 0; i < HEIGHT; ++i)
matrix0[i] = new float[WIDTH];
// Доступ
for (int i = 0; i < HEIGHT; ++i)
for (int j = 0; j < WIDTH; ++j)
matrix0[i][j] = 0;
const long WIDTH = 100;
const long HEIGHT = 100;
float* matrix1;
// Аллокация
matrix1 = new float[WIDTH*HEIGHT];
// Доступ
for (int i = 0; i < HEIGHT; ++i)
for (int j = 0; j < WIDTH; ++j)
matrix1[i * WIDTH + j] = 0;
Shared memory