Параллельные и распределенные вычисления
Семинар 8
Hadoop streaming API
Пономаренко Роман
@rerand0m
rerandom@ispras.ru


Что сегодня потребуется
ssh USER@mipt-client.atp-fivt.org -L 8088:mipt-master:8088 -L 19888:mipt-master:19888 -L 8888:mipt-node03:8888 # USER подставить свой
:8888 - hue
:8088 - hadoop cluster state
:19888 - hadoop history
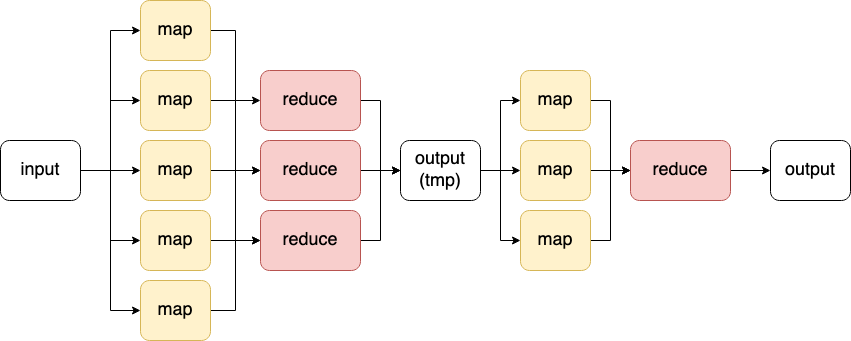
Hadoop streaming interface
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \
-D mapreduce.job.name="my_awesome_job_name" \
-files file0,file1,file2 \ # dfc
-input /data/wiki/en_articles_part \
-output mr_result
Mapper
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapreduce.job.name="my_awesome_job_name" \ -mapper mapper.py \ -files mapper.py \ # dfc -input /data/wiki/en_articles_part \ -output mr_result
Reducer
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapreduce.job.name="my_awesome_job_name" \ -mapper mapper.py \ -reducer reducer.py \ -files mapper.py,reducer.py \ # dfc -input /data/wiki/en_articles_part \ -output mr_result
Combiner
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapreduce.job.name="my_awesome_job_name" \ -mapper mapper.py \ -combiner reducer.py \ -reducer reducer.py \ -files mapper.py,reducer.py \ # dfc -input /data/wiki/en_articles_part \ -output mr_result
Счётчики
В stderr вывести текст в формате:
reporter:counter:<Topic>,<counter_name>,<value>
Затем в выводе yarn:
INFO mapreduce.Job: Counters: 51 ... <Topic> counter1=4966256 counter2=11937375 ...