Параллельные и распределенные вычисления
Семинар 9
Hadoop Java API
Пономаренко Роман
@rerand0m
rerandom@ispras.ru

Hadoop Streaming API
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapreduce.job.name="my_awesome_job_name" \ -mapper mapper.py \ -combiner reducer.py \ -reducer reducer.py \ -files mapper.py,reducer.py \ # dfc -input /data/wiki/en_articles_part \ -output mr_result
Hadoop Java API
job.setInputFormatClass
TextInputFormat
вход маппера:(LongWritable offset, Text rawString)
+ самый быстрыйKeyValueTextInputFormat
хранит информацию о простых типах (например:IntWritable, Text)SequenceFileInputFormat
хранит информацию о любых*Writable*типах
- вывести через-catне получится
Writable
Для обеспечения сериализации/десериализации есть интерфейсы
WritableиWritableComparable.Для ключей необходимо использовать
WritableComparable.Для значений достаточно
Writable.- Типы, предоставляемые Hadoop API -
WritableComparable.
Число Reducer
streaming API
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \ -D mapreduce.job.name="my_awesome_job_name" \ -D mapreduce.job.reduces=${NUM_REDUCERS} \ -mapper mapper.py \ -combiner reducer.py \ -reducer reducer.py \ -files mapper.py,reducer.py \ # dfc -input /data/wiki/en_articles_part \ -output mr_result
Java API
TotalOrderPartitioner
RandomSampler
Такой Sampler запускается на mapper, поэтому есть требование, чтобы он не менял сигнатуру данных (особенность реализации).
Join
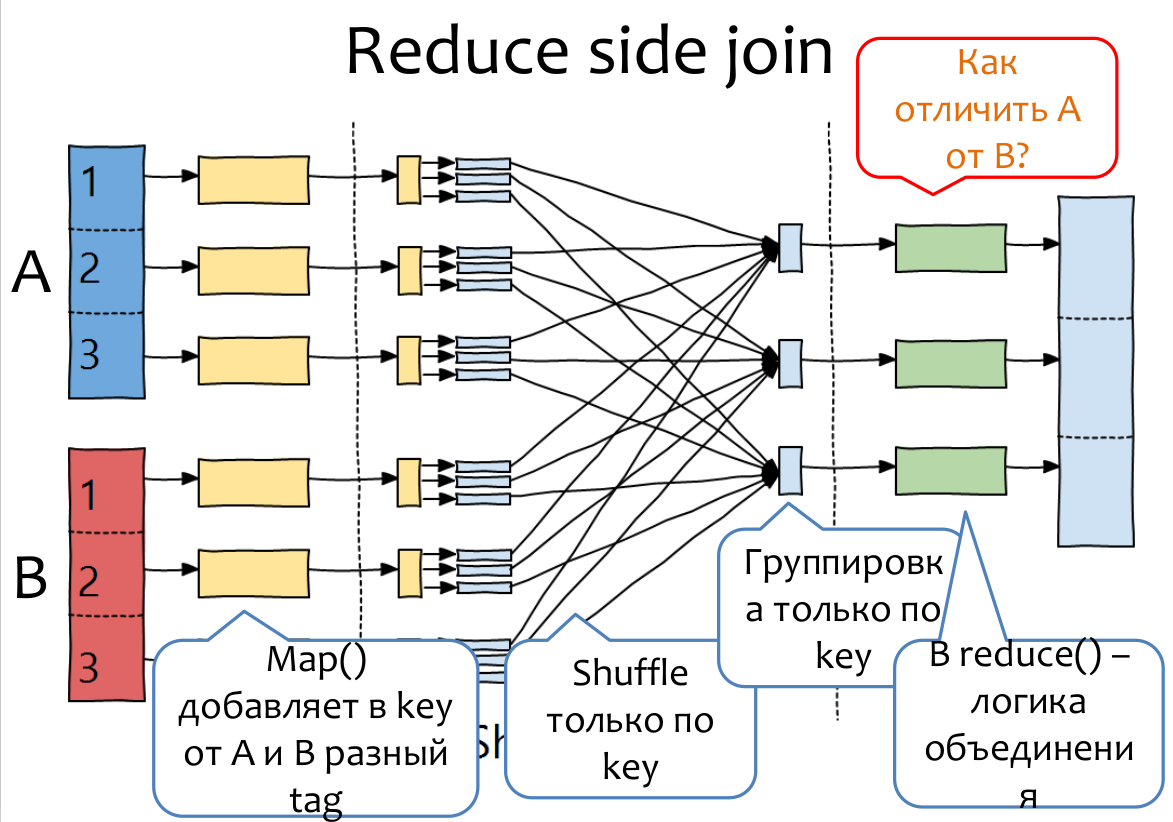
Join
Посчитать число вопросов и ответов по возрастам
/data/stackexchange/posts - посты
/data/stackexchange/users - пользователи
Join
- 1. MAP: сформировать данные в формате:
(userid, age, q, a) - 1. REDUCE: преобразовать в формат:
(age, q, a) - 2. MAP: stub
- 2. REDUCE: доагрегировать данные после сортировки по возрасту