Параллельные и распределенные вычисления
Семинар 12
Spark
Пономаренко Роман
@rerand0m
rerandom@ispras.ru

Spark
- Выполняет вычисления лениво
- Между операциями не сохраняет промежуточный результат на диск
- Может резервировать "контейнеры" для вычислений
- Подходит для обработки данных в реальном времени
- Существуют API для Java, Scala, Python, R
Spark stack

Spark sources
Spark components
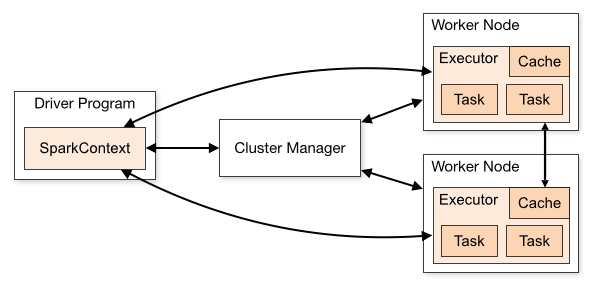
Запуск в spark
Интерактивная оболочка:
spark2-shell- scala оболочкаpyspark2- python оболочка
Запуск файла на исполнение:
spark2-submit [params] <file>
(Можно подавать на вход как py, так и jar файлы)
Запуск Jupyter notebook
Userguide по работе со Spark в кластере МФТИ
Resilient Distributed Dataset
Основной примитив для работы в Spark.
Набор данных, распределённый по партициям (аналог сплитов в Hadoop).
Свойства:
- Неизменяемый. Можем получить либо новый RDD, либо plain object.
- Итерируемый. Можем делать обход RDD.
- Восстанавливаемый. Каждая партиция помнит как она была получена (часть графа вычислений) и при утере может быть восстановлена.
Типы операций в Spark
- Трансформации - преобразуют RDD в новый RDD
- Действия - преобразуют RDD в обычный объект
В основном, трансформации - ленивые.
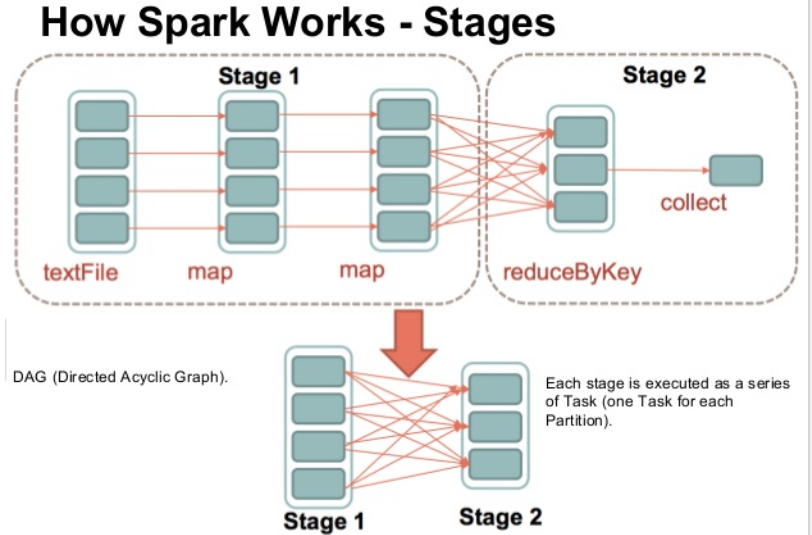
Task << Stage << Job << Application.
Аккумуляторы
Аналоги счётчиков в Hadoop
cnt = sc.accumulator(start_val)
foreach(lambda x: cnt.add(x))
def count_with_conditions(x):
global cnt
if ...:
cnt += 1
rdd.foreach(lambda x: count_with_conditions(x))
cnt.value
Broadcast переменные
Аналог DistributedCache в Hadoop. Обычно используется когда мы хотим в спарке сделать Map-side join
br_cast = sc.broadcast(["hadoop", "hive", "spark", 'zookeeper', 'kafka'])
Cache
cache()- кэширование в RAMpersist()- можно задать, куда кэшировать